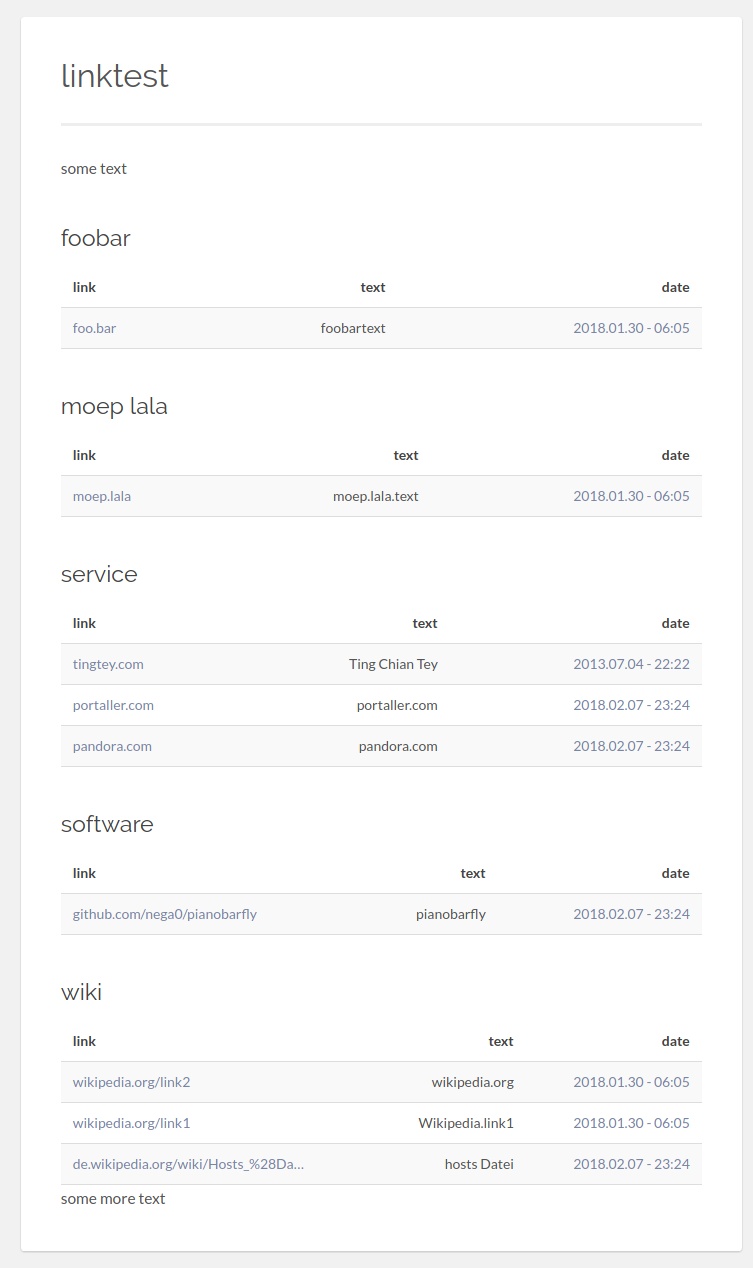
Ok, here is the code, if anyone is interested in. maybe it is a help for someone.
Since, the markdown-extra tables are not very comfortable to align and multiple head-lines are not supported, i will change my original idea and write my own html table and/or tab based template. also i’m not sure which data i will output. so, here is a sample output you will have to modifiy for yourself. at this stage, i think, every change will just help myself and not anyone else… so here are my findings/is my code.
- The Plugin analyses the raw content files for Markdown Links which are extended by a
tag:attribut. - Original: (link: http://wikipedia.de text: wikipedia Website)
- New: (link: http://wikipedia.de tag: wiki text: wikipedia Website)
- when you use the new snippet tag in any of your pages, you will get a table of link collection.
site/snippets/linksnippet.php
<div>
<?php
$items = page('home')->children()->visible();
foreach($items as $item) {
page::$methods['getTaggedLinklist'] = function($page, $field = null) {
if(!is_null($field) && in_array($field, $page->content()->fields())) {
$raw = $page->{$field}();
} else {
$raw = $page->content()->raw();
}
// find all tags
preg_match_all('!`[^``]*`(*SKIP)(*F)|\(([^)]+\))!', $raw, $matches);
$list = [];
if(count($matches[0]) > 0) {
// loop through the matches
foreach($matches[0] as $match) {
// remove the brackets
$tag = trim(rtrim(ltrim($match, '('), ')'));
// get the name of the tag
$name = trim(substr($tag, 0, strpos($tag, ':')));
// check if it is a link tag
if($name == 'link') {
// create a new Kirbytag instance
$tag = new Kirbytag(null, $name, $tag);
// check if tag is included
if(!is_null($tag->attr('tag'))) {
// get all the attributes and add them to our list
$list[] = $tag->attr();
}
}
}
}
return $list;
};
foreach($item->getTaggedLinklist() as $element) {
// define content of each link-array
if(empty($element['text'])) {
$textelement = parse_url($element['link'], PHP_URL_HOST);
} else {
$textelement = $element['text'];
}
$output = array(
'tag' => $element['tag'],
'link' => $element['link'],
'text' => $textelement,
'pagetitle' => $item->title()->value(),
'pagelink' => $item->url(),
'date' => $item->date()
);
$key = $element['tag'];
$full[$key][] = $output; // add link-array to tag-group
// filter duplicate links while
$temparr = array_unique(array_column($full[$key], 'link'));
$finalarray[$key] = array_intersect_key($full[$key], $temparr);
// sort each element in a tag-group by date
usort($finalarray[$key], function($a, $b) {
return $a['date'] - $b['date'];
}
);
}
}
// sort tag-groups by alphabet
uksort($finalarray, 'strcasecmp');
// generate markdown table of array
$tgmt = "\n"; // tag group markdown table
foreach($finalarray as $taggroupname => $taggroup) {
$tgmt .= '### ' . $taggroupname . "\n";
$tgmt .= '|link|text|date|' . "\n"; // table header
$tgmt .= '|--|--:|--:|' . "\n";
foreach($taggroup as $tgi) { // taggroupitem
// convert unix timestamp
$timeconv = date('Y.m.d - H:i', $tgi['date']);
// generate table row
$linkstring = url::short($tgi['link'], 33);
$link = '(link: ' . $tgi['link'] . ' text: ' . $linkstring . ')';
$tgmt .= '|' . $link . '|' . $tgi['text'] . '|(link: ' . $tgi['pagelink'] . ' text: ' . $timeconv . ')|' . "\n";
}
}
echo kirbytext($tgmt);
?>
</div>
site/tag/link.php
<?php
// link tag
kirbytext::$tags['link'] = array(
'attr' => array(
'text',
'class',
'role',
'title',
'rel',
'lang',
'target',
'popup',
'tag'
),
'html' => function($tag) {
$link = url($tag->attr('link'), $tag->attr('lang'));
$text = $tag->attr('text');
if(empty($text)) {
$text = $link;
}
if(str::isURL($text)) {
$text = url::short($text);
}
return html::a($link, $text, array(
'rel' => $tag->attr('rel'),
'class' => $tag->attr('class'),
'role' => $tag->attr('role'),
'title' => $tag->attr('title'),
'target' => $tag->target(),
));
}
);
site/tag/snippet.php
<?php
kirbytext::$tags['snippet'] = array(
'attr' => array(
),
'html' => function($tag) {
$file = $tag->attr('snippet');
return snippet($file, array(), true);
}
);
some notes:
- links inside codeblocks or inline-code are ignored
- duplicate links are ignored
- invisible pages are ignored
- output is sorted by tag and by date
- when text attribute is empty, the hostname of the link is used as text
- tags are case-sensitive
- take a look at linksnippet.php to get an idea of outputcode
- i’m not a coder. those few lines of code cost me a lot of time. most of you will laugh on the ugly code, the ugly structure and time i wasted. i know, the most of you would write something like this is an hour or less. for me it took several full days of finding code snippets and trying to understand them.
- thx a lot to @texnixe for your help.
- also a lot help was the idea of this thread: Embedding Snippets
Include in site

possible output (with align-problem)